前言
博主之前用过C#写爬虫,被本学期学过Python后,冲着其:简单,干净,快捷的优点,就决定学下Python爬虫,下面记载使用Python做一个酷狗音乐下载的爬虫,和实现过程中遇到的问题,如果你也在学Python爬虫,希望这篇文章能给你带来一些帮助。
什么是爬虫?
- 访问网址,抓取其html文档或者Json文档,对于某些网站具有反爬虫机制,所以需要模拟浏览器的用户代理(User Agent)的行为构造请求。
- 筛选出第一步拿到的网页数据,筛选出需要的数据
获取搜索音乐列表Json
通过网页解析网页从而拿到音乐数据。我们知道在酷狗中搜索歌曲时会访问一个固定的网址+搜索内容获取数据,如:https://www.kugou.com/yy/html/search.html#searchType=song&searchKeyWord=卡路里
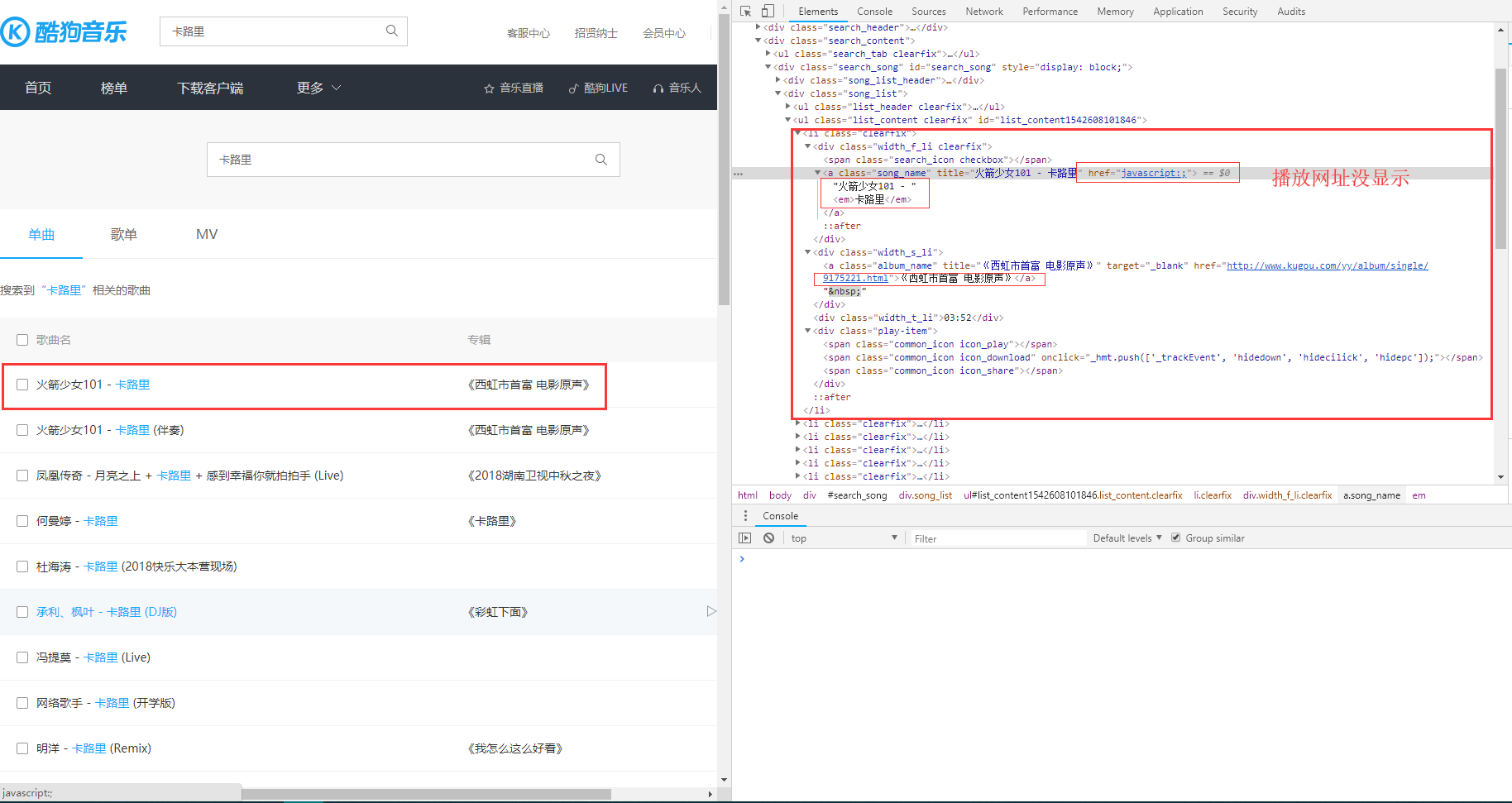
找到网页请求的Json数据,然后解析出来:老规矩F12。嗯,找到了:
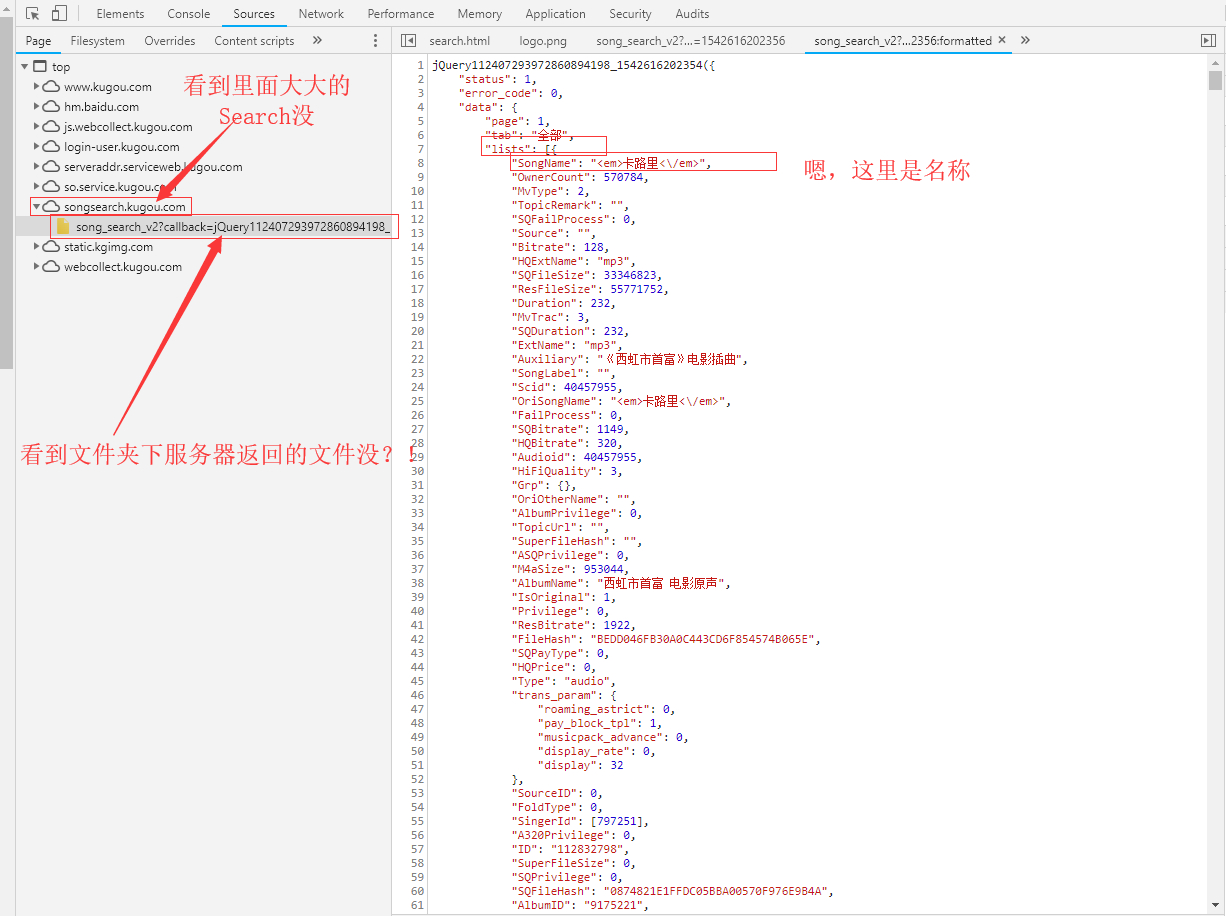
看下地址,https://songsearch.kugou.com/song_search_v2?callback=jQuery112407293972860894198_1542616202354&keyword=卡路里&page=1&pagesize=30&userid=-1&clientver=&platform=WebFilter&tag=em&filter=2&iscorrection=1&privilege_filter=0&_=1542616202356我们就可以通过此链接获取无门需要搜索歌曲的列表。但是分析下这个文件还是没有找到播放音乐的url,额…继续找…
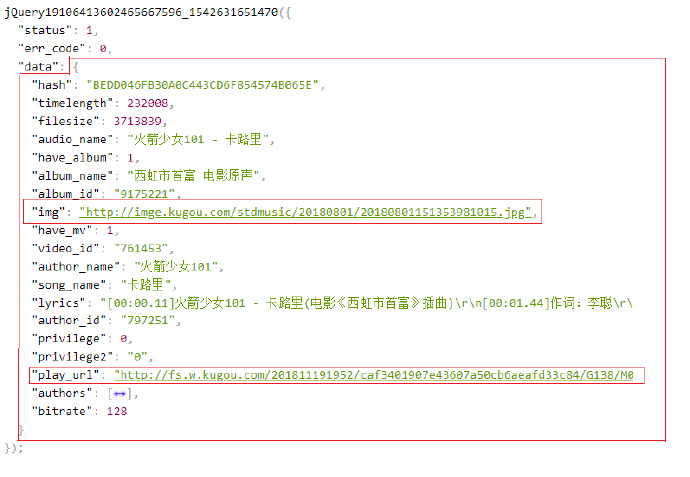
获取歌曲信息Json
点开一个音乐播放的条目,F12分析:
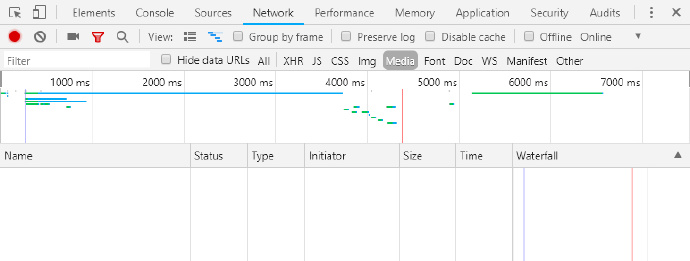
竟然不存在音频文件,但事实音乐已经开始播放了,并且自动播放的。那只能说明播放音乐的url依然不再这里,老办法,查找json文件:
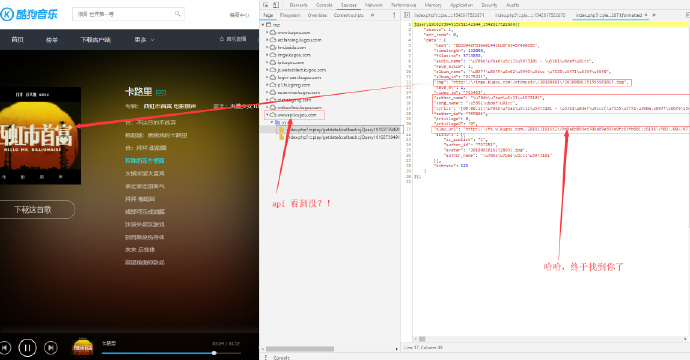
嗯,没看错,就是在这里,那么获取这个的json的url是什么呢?怎么得到呢?
看链接:https://www.kugou.com/song/#hash=BEDD046FB30A0C443CD6F854574B065E&album_id=9175221 也是一个固定的字符串与hash,album_id 组成的。那问题就变成了如何获取hash 和 album_id. 还记得之前获取的音乐列表的信息吗,当时只看懂了SongName,仔细对比查看:
FileHash 对应 hash
AlbumID 对应 album_id
Json处理
上面获取的音乐列表,音乐详细信息都不是标准的json文本,我们需要的是将其更正为标准的json

代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| import requests
import json
import re
def get_song_list_json(unjson):
start_index = unjson.index('[')
end_index = unjson.rindex(']')
unjson = unjson[start_index: end_index]
end_index = unjson.rindex(']')
str_json = unjson[0:end_index] + ']'
return str_json
def get_music_info_json(unjson):
start_index = unjson.index('{')
end_index = unjson.rindex('}')
unjson = unjson[start_index: end_index]
start_index = unjson.index('{', 1)
unjson = unjson[start_index: -1]+'}'
return unjson
def get_play_url(filehash, id=0):
return 'https://www.kugou.com/song/#hash=' + filehash+'&album_id='+id
def get_download_api(callback, hash, id):
return 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback='+callback+'&hash='+hash
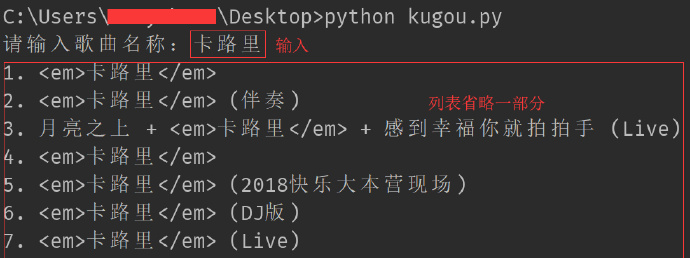
song_name = input("请输入歌曲名称:")
url = 'https://songsearch.kugou.com/song_search_v2?callback=jQuery1124043482941576795797_1542458757544&keyword={0}&page=1&pagesize=30&userid=-1&clientver=&platform=WebFilter&tag=em&filter=2&iscorrection=1&privilege_filter=0&_=1542458757546'.format(song_name)
content = requests.get(url).text
callback_end_index = content.index('(')
callback = content[0: callback_end_index]
content = get_song_list_json(content)
music_list = json.loads(content)
imforlist = []
num = 1
for item in music_list:
imforlist.append(item)
print(str(num)+'. ' + dict(item)['SongName'])
num = int(num)+1
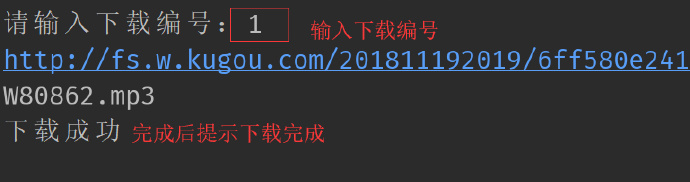
id = input('请输入下载编号:')
if int(id) > 0 and int(id) <= int(num):
item = dict(imforlist[int(id)-1])
download_api = get_download_api(callback, item['FileHash'], item['AlbumID'])
unjson = requests.get(download_api).text
download_url = re.findall(r'"play_url":"(.*?)"', unjson)
download_url = str(download_url[0]).replace("\/", "/")
print(download_url)
with open(str(id)+'.mp3', 'wb') as fp:
fp.write(requests.get(download_url).content)
print('下载成功')
|
运行结果
仅供学习使用,用于商业用途,本人不负责!
TonyChenn
2018.11.19

