dictionary官方源码地址
要点
主要实现IDictionary接口
底层通过hash table实现,数据结构是数组。所以同样不适合频繁插入操作,但是查找效率高
同样是线程不安全,多线程需要手动处理。
关键步骤 1. 计算hash code, 2. 解决哈希冲突(拉链法)
扩容操作:大于 旧容量2倍 的最小质数。删除操作不改变容量
添加数据采用头插法
key具有唯一性,且不能为空。
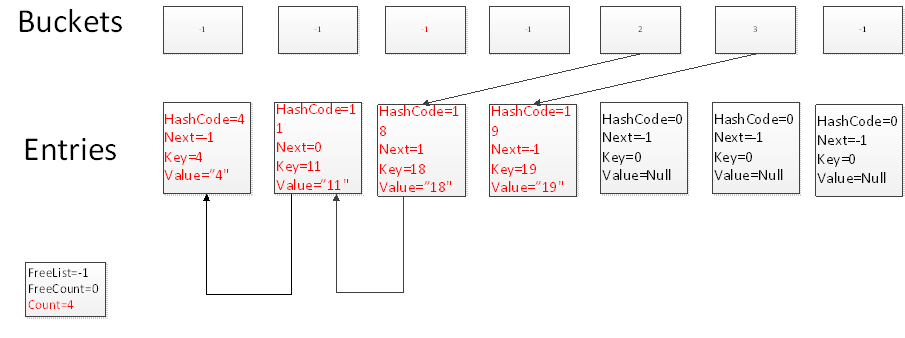
关键数据结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 private struct Entry{ public int hashCode; public int next; public TKey key; public TValue value ; } private int [] buckets; private Entry[] entries; private int count; private int version; private int freeList; private int freeCount; private IEqualityComparer<TKey> comparer; private KeyCollection keys; private ValueCollection values;
freeList相当于是一个存放移除掉元素的对象池。当添加新数据时首先从池里取出对象。
初始化字典 new一个字典时可以传递一个数字capacity来初始化字典的大小。当然传入的大小并一定是字典的大小,是要通过HashHelpers.GetPrime方法获取一个比capacity大的一个最小质数。
1 2 3 4 5 6 7 8 9 10 11 12 private void Initialize (int capacity{ int prime = HashHelpers.GetPrime(capacity); buckets = new int [prime]; for (int i = 0 ; i < buckets.Length; i++) { buckets[i] = -1 ; } entries = new Entry[prime]; freeList = -1 ; }
插入数据 是Add(key, value)和索引器dict[key] = value的具体实现。不同的是:当字典中如果已经存在某个键时再次通过Add方法会抛出异常,因为key具有唯一性。但是通过索引器则不会抛异常,此时是将新的value覆盖旧的value。所以通过索引器比add方法安全一些。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 private void Insert (TKey key, TValue value , bool add ){ if (key == null ) ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key); if (buckets == null ) Initialize(0 ); int num = comparer.GetHashCode(key) & 0x7FFFFFFF ; int num2 = num % buckets.Length; int num3 = 0 ; for (int num4 = buckets[num2]; num4 >= 0 ; num4 = entries[num4].next) { if (entries[num4].hashCode == num && comparer.Equals(entries[num4].key, key)) { if (add ) { ThrowHelper.ThrowArgumentException(ExceptionResource.Argument_AddingDuplicate); } entries[num4].value = value ; version++; return ; } num3++; } int num5; if (freeCount > 0 ) { num5 = freeList; freeList = entries[num5].next; freeCount--; } else { if (count == entries.Length) { Resize(); num2 = num % buckets.Length; } num5 = count; count++; } entries[num5].hashCode = num; entries[num5].next = buckets[num2]; entries[num5].key = key; entries[num5].value = value ; buckets[num2] = num5; version++; if (num3 > 100 && HashHelpers.IsWellKnownEqualityComparer(comparer)) { comparer = (IEqualityComparer<TKey>)HashHelpers.GetRandomizedEqualityComparer(comparer); Resize(entries.Length, forceNewHashCodes: true ); } }
动态扩容 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 private void Resize (int newSize, bool forceNewHashCodes{ int [] array = new int [newSize]; for (int i = 0 ; i < array.Length; i++) array[i] = -1 ; Entry[] array2 = new Entry[newSize]; Array.Copy(entries, 0 , array2, 0 , count); if (forceNewHashCodes) { for (int j = 0 ; j < count; j++) { if (array2[j].hashCode != -1 ) { array2[j].hashCode = comparer.GetHashCode(array2[j].key) & 0x7FFFFFFF ; } } } for (int k = 0 ; k < count; k++) { if (array2[k].hashCode >= 0 ) { int num = array2[k].hashCode % newSize; array2[k].next = array[num]; array[num] = k; } } buckets = array; entries = array2; }
哈希冲突及解决方案 对于key1 != key2, hash(key1) == hash(key2)的情况就是哈希冲突。通常情况下,哈希冲突只能尽可能减少,而不能完全避免。解决哈希冲突的常见方法有如下:开放定址法、再哈希法、拉链法等。本文中字典中就是使用拉链法。
拉链法原理
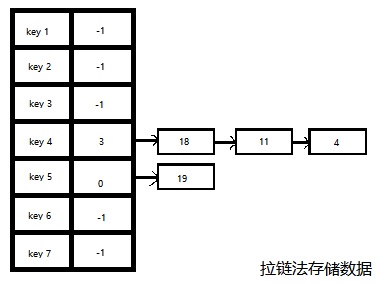
将所有关键字为同义词的结点链接在同一个单链表中。若选定的散列表长度为n,则可将散列表定义为一个由n个头指针组成的指针数 组T[0..n-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。如下图所示:
上图可以直观的描述出链式结构,但实际上并非是真正的单链表,而是使用数组模拟出来的’假链表’,其next指针记录的是下一个节点的索引,这样的优点是避免了开辟了一个大的entrys空间,又开辟一堆小的链式空间,节约内存使用。所以笔者认为下图可以更加正确的描述出每个节点在数组中的存储状态。
删除数据,查找数据 首先根据key计算出索引。然后到对应数据桶中比较key是不是相同,不相同就查找下一个节点,直到遍历到尾结点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 private int FindEntry (TKey key ){ if (key == null ) ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key); if (buckets != null ) { int num = comparer.GetHashCode(key) & 0x7FFFFFFF ; for (int num2 = buckets[num % buckets.Length]; num2 >= 0 ; num2 = entries[num2].next) { if (entries[num2].hashCode == num && comparer.Equals(entries[num2].key, key)) { return num2; } } } return -1 ; }
为什么查找效率高? 查找时可以通过key来计算key所在的索引,在理想情况下(无哈希冲突),通过索引直接获得值,时间复杂度O(1)。随着哈希冲突增多而逐渐增高,最坏情况O(n)。
时间复杂度分析
O(1)
Add,Containskey, dict[key]
O(n)
ContainsValue
优化点
创建字典时分配字典大小,减少字典内部进行扩容操作。
字典的key为数值类型时比对象作为key时效率高。
参考